AWS S3 + Athena real-time business analytics
Business metrics are stored in a database, logs, files or a dedicated warehouse. In this article we’re going to implement real-time business analytics in AWS S3 using AWS Athena.
AWS S3 is a simple object storage service. It is highly available (99.9%) and durable ( 99.999999999%).
AWS Athena is a service to query data (basically files with records) in S3 using SQL. Athena supports querying CSV, JSON, Apache Parquet data formats.
- It’s serverless! You don’t need to set up or maintain hosts/databases.
- You pay per query! 1TB of scanned data = 5$
- You can use it with different business intelligence or SQL clients.
How Athena works? Athena uses Presto under the hood. What is Presto?

Getting back to our topic, let’s say we have an online bookstore, and we need business metrics for books purchases. Books purchases are processed by PurchaseService.
Let’s define the metrics metadata:
{
"bookId": "ec437d98-455d-4fec-8dbe-2c2630454bdd",
"title": "Orlando",
"author": "Virginia Woolf",
"genre": "Fiction",
"userId": "test-user",
"userCountry": "country",
"userAge": 24,
"purchaseTimestamp": 1575121641
}
Now we can publish our purchase metrics directly to S3, but AWS Kinesis Firehose is better and here is why:
- Firehose buffers incoming records and delivers in batches.
- Firehose can convert the records to another data format, for example Apache Parquet (which is much more efficient for Athena querying - 1TB of JSON records reducing down to 130GB, meaning faster and cheaper querying)
- Firehose can compress the data (gzip, snappy, etc.)
Let’s create a Firehose stream in AWS Console called books-purchase-stream that delivers data to S3. PurchaseService is a NodeJS AWS Lambda Function and it will publish purchase events (purchase metrics format we defined recently) to books-purchase-stream.
const AWS = require('aws-sdk');
const firehose = new AWS.Firehose();
const firehoseStream = "books-purchase-stream"
exports.metricsPublisher = function(event, context) {
const purchaseRecord = JSON.stringify(event);
const firehoseRecord = {
DeliveryStreamName: firehoseStream,
Record: {
Data: purchaseRecord
}
};
firehose.putRecord(firehoseRecord, function(error, data) {
if (error) {
console.log(error, error.stack);
}
else {
console.log(data);
}
context.done();
});
};
Now we have the metrics stored in S3, how do we query it?
Athena is integrated with AWS Glue Data Catalog and requires a Glue database and a Glue table for querying. AWS Glue Data Catalog is a metadata repository, a Glue table is the data model (schema) and a Glue database contains tables.
To create a Glue database and a table with our purchase metrics metadata we’re gonna use a Glue Crawler. Point a Glue Crawler to the data in S3 and the crawler will extract the metadata into AWS Glue Data Catalog.
The flow we’ve created so far:
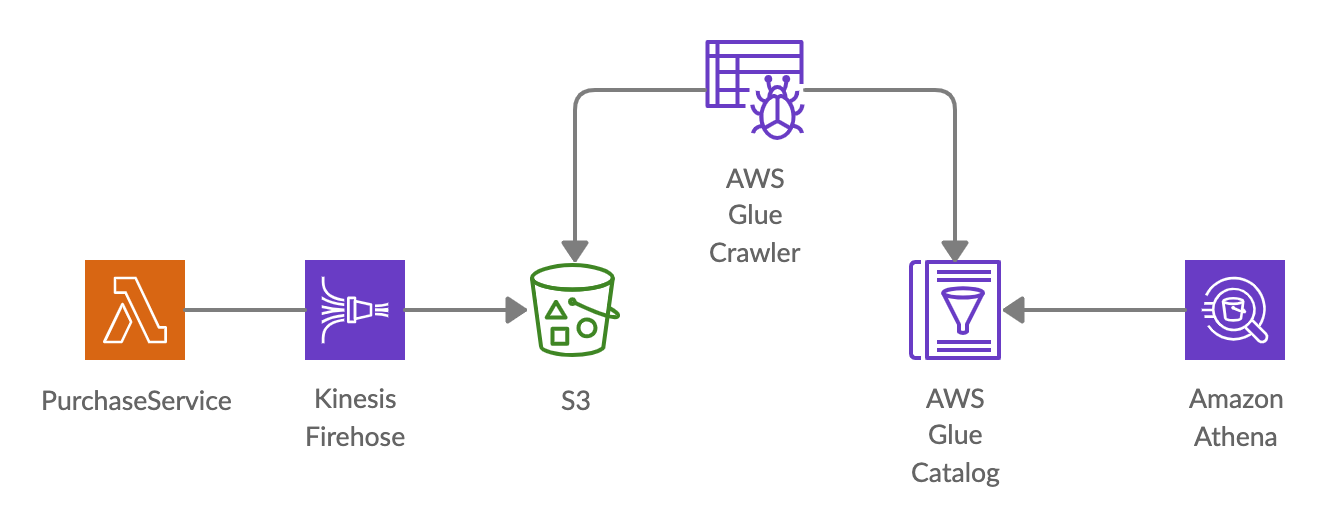
The purchase metrics are in AWS S3 and purchase metrics metadata in AWS Glue Catalog, can we query it now?
Yes! Let’s go to Athena and write a simple query:
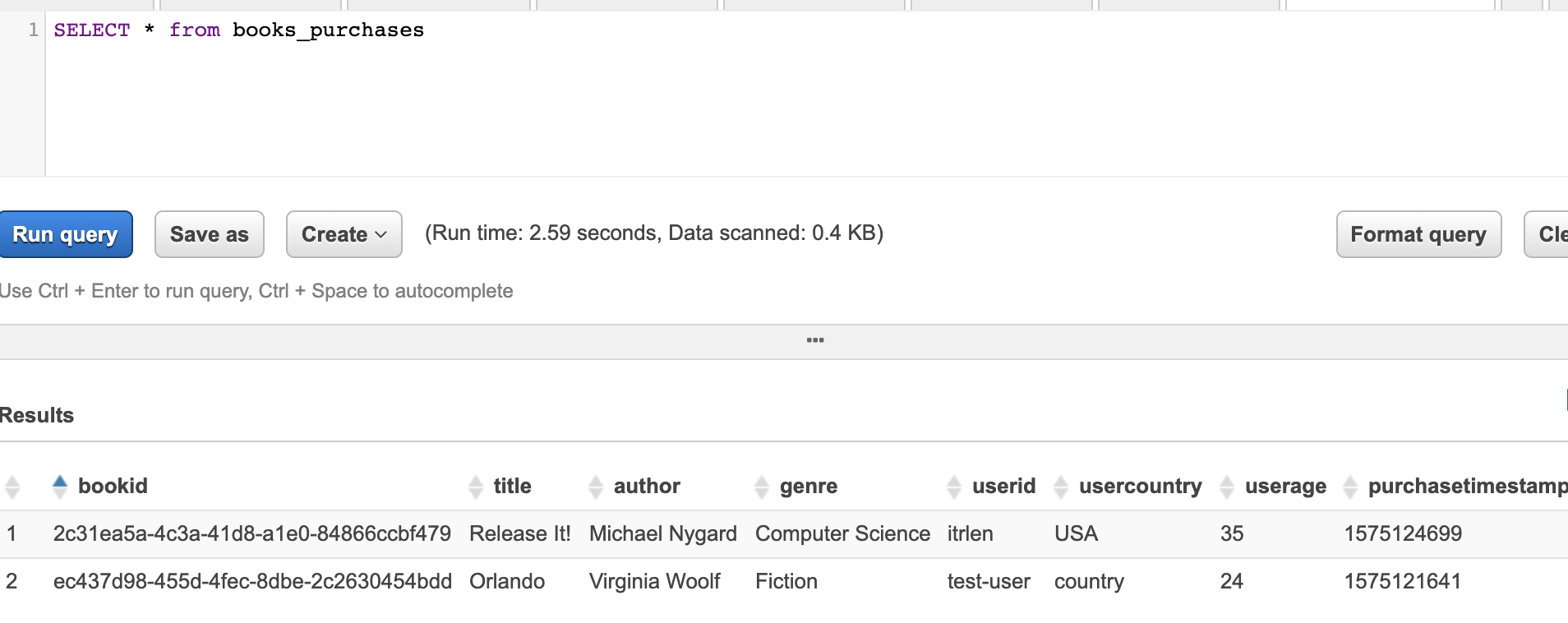
Conclusion
In the end we have a simple yet powerful serverless real-time business analytics infrastructure.
References
Share on: